Couple days ago I wrote a quick post demonstrating how to find duplicate records in a SQL server table. A colleague of mine read the post and asked me to show how to delete the duplicates from the table. Therefore, I thought it would make sense I put this post together on how to delete duplicate entries in a table.
What does it take to remove duplicates from a table?
- First, we need to validate the data to see the duplicates we are deleting.
WITH student_cte AS ( SELECT First_Name, Last_Name, Phone, ROW_NUMBER() OVER( PARTITION BY First_Name, Last_Name, Phone ORDER BY First_Name, Last_Name, Phone ) rn FROM dbo.Students ) select * from student_cte;
- The picture below shows the records that are duplicates with the row count.
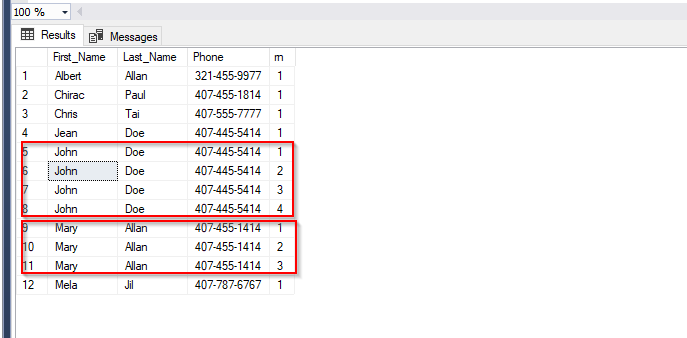
- Now, in order to delete these record, I am going to show the best way to handle using that same CTE query above with a slight modification. I have deleted any instance with rn > 1.
WITH student_cte AS ( SELECT First_Name, Last_Name, Phone, ROW_NUMBER() OVER( PARTITION BY First_Name, Last_Name, Phone ORDER BY First_Name, Last_Name, Phone ) rn FROM dbo.Students ) DELETE FROM student_cte WHERE rn >1; -
After running the query above, the duplicated records are now gone.
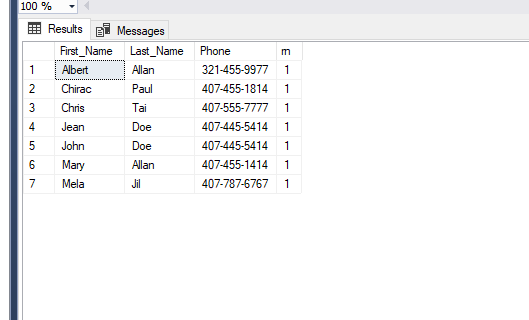
In this post, I showed how you can get rid of duplicate rows from a table in SQL Server. I hope after reading this article you will be able to use these tips. If you have questions or feedback, please share it with me. I’d like to know what you’re thinking. Please post your feedback, question, or comments about this article.